On a recent project for a client, I ran into a problem that turned out to be more interesting than I expected, so I wanted to write it down and share it as a use case.
The system is a marketplace that lets you search for specialists, see which of them are online right now, and start a chat or a call with them. The part I want to talk about is the “online right now” part, because keeping that both fast and accurate was harder than it sounds. There is also a complete proof of concept that runs locally with a single docker compose command, and I link to the relevant parts of it throughout.
TL;DR
I had to serve a listing that came from older, legacy systems, and it had to be both fast and accurate, without doing a major refactoring of those systems first. Caching made it fast, but the cache kept going stale, because several systems wrote to the data directly and I had no single place to invalidate the cache from.
The approach I took was to stop trying to catch the writes, and instead detect the changes at the database. Debezium reads the MySQL binary log, sends each change to a Redis Stream, and a small background worker reads that stream, recomputes the current state from the database, and updates the cache.
This was built under specific constraints, the main one being that I cannot guard the writes. I describe a cleaner, more ideal solution further down, for the case where you can.
The problem 💲💵
A customer searches for specialists, sees someone listed as online, and starts a session with them — only to find that the specialist is not actually free. That is a frustrating experience for the customer, and from the business side it is a missed session and a missed bit of revenue, from someone who was ready to pay right then. Showing the wrong status has a real cost, so “roughly correct” was not good enough.
Reading the live status directly was slow, so the obvious move was to cache it. The difficulty was keeping the cached value correct, because the data did not come from one clean place.
There were several older systems behind it, including an old IVR system and a few legacy applications. They are not versioned well, and some of them write to the database directly. I could not easily change them, and I could not put them all behind a single service yet. So whatever solution I picked had to work around them, not through them.
The first attempt, and why it failed
My first version was simple: I cached the status and refreshed it on a timer. This did not work well. The data was late, often stale, and sometimes simply wrong, because a timer does not know when something actually changed — it only knows that some time has passed. For those few seconds between refreshes, the screen could show someone as online after they had already left, or offline right after they came back.
I could shorten the timer, but that only moved the problem: more load, and still no guarantee. The real issue was that I was guessing when to refresh, instead of knowing.
Why normal cache invalidation did not fit
The usual answer is to invalidate the cache at the moment of the write — when a write happens, you clear or update the cache in the same code path. But that only works if every write goes through code you control, and in my case it did not. Multiple systems wrote to the database, the old IVR system among them, some of them directly, and I could not guarantee that all of them, now and in the future, would call my invalidation logic. The moment one writer skips it, the cache is stale again and nobody notices.
So I needed something that did not depend on the writers cooperating. That is the core idea of this whole post: when you cannot guard the writes, detect the change at the database instead.
React at the database, not at the writer
There is one place where every write always ends up, no matter which system made it: the database itself. So instead of catching the change at each writer, I catch it at the database.
This is Change Data Capture (CDC). The database already keeps a log of what changed, which it uses for its own replication and recovery. CDC means reading that log and turning each change into an event that other systems can react to.
I looked at a few ways to detect changes. Some of them write extra bookkeeping back into the production database, which I wanted to avoid. I chose Debezium mainly because it is non-invasive: it connects like a replica, reads the log, and does not write anything back to the application data. From the database’s point of view, it is just another reader.
What I built
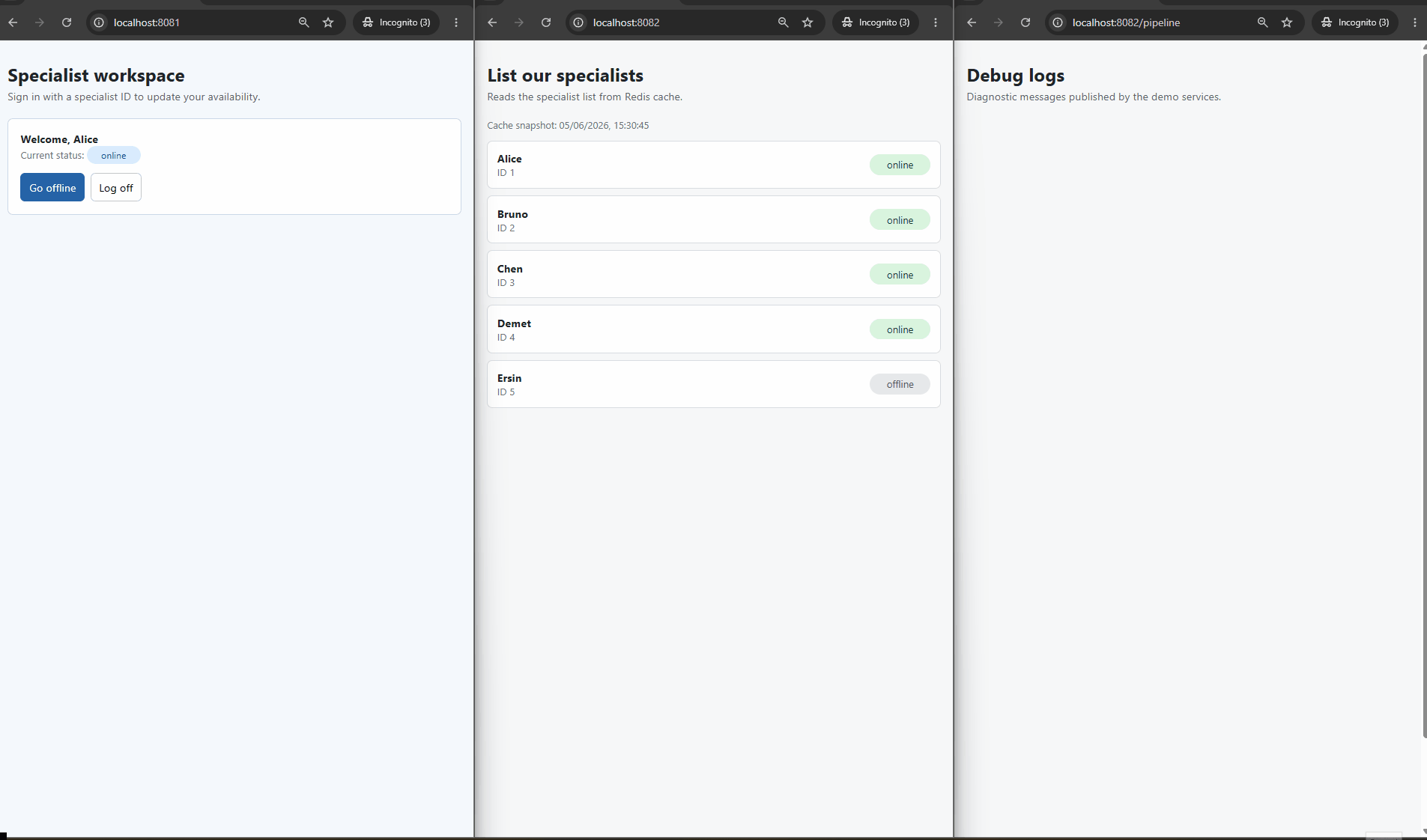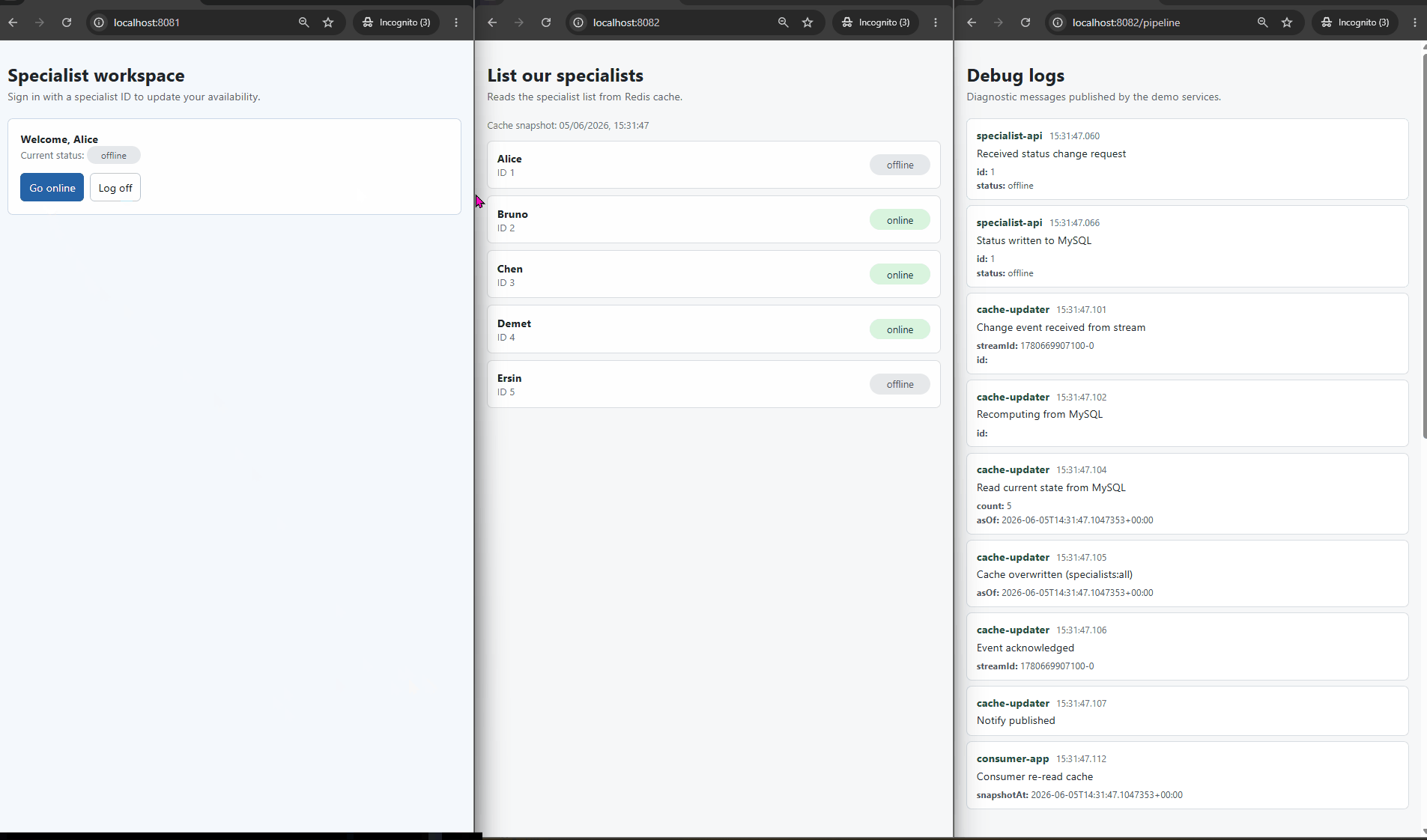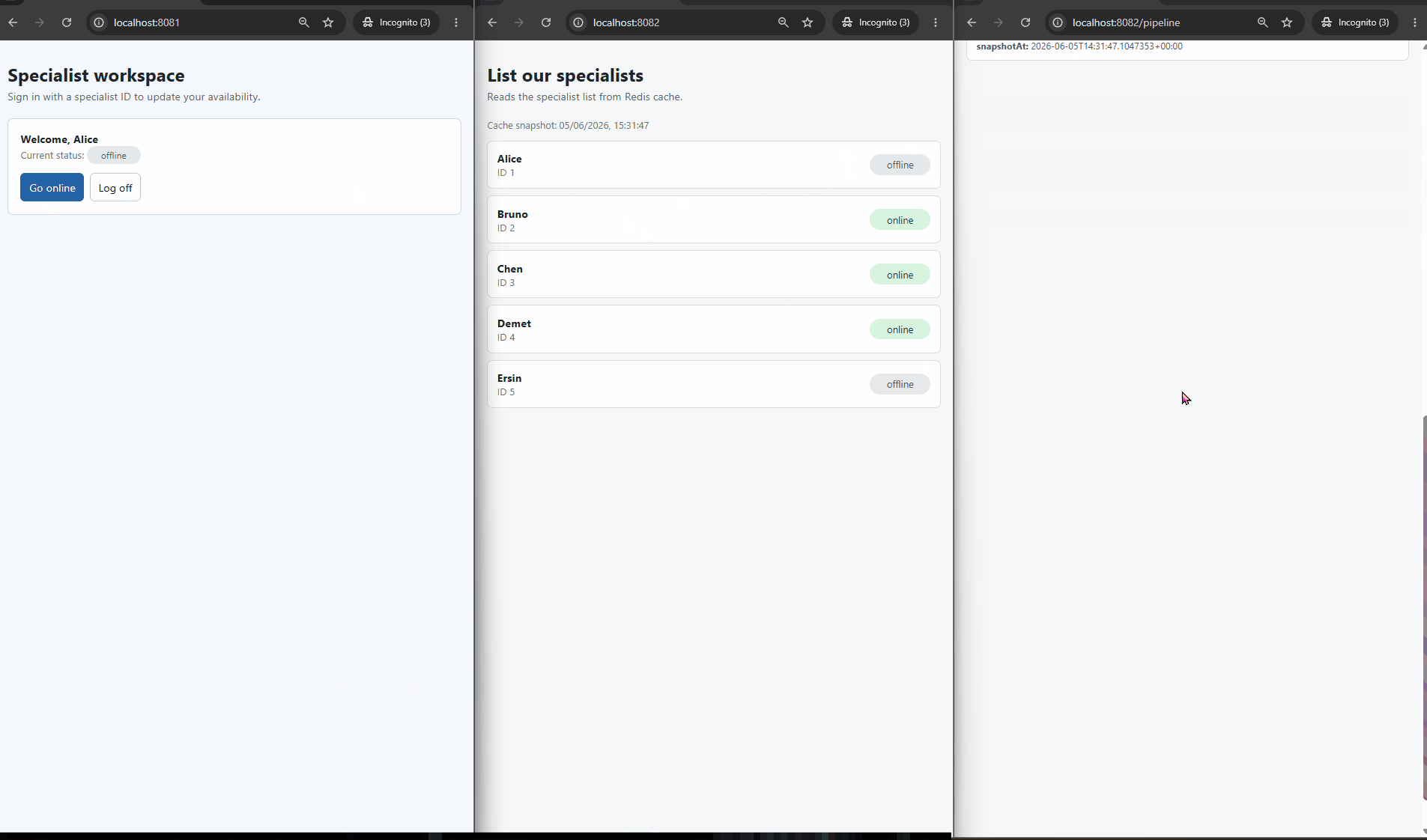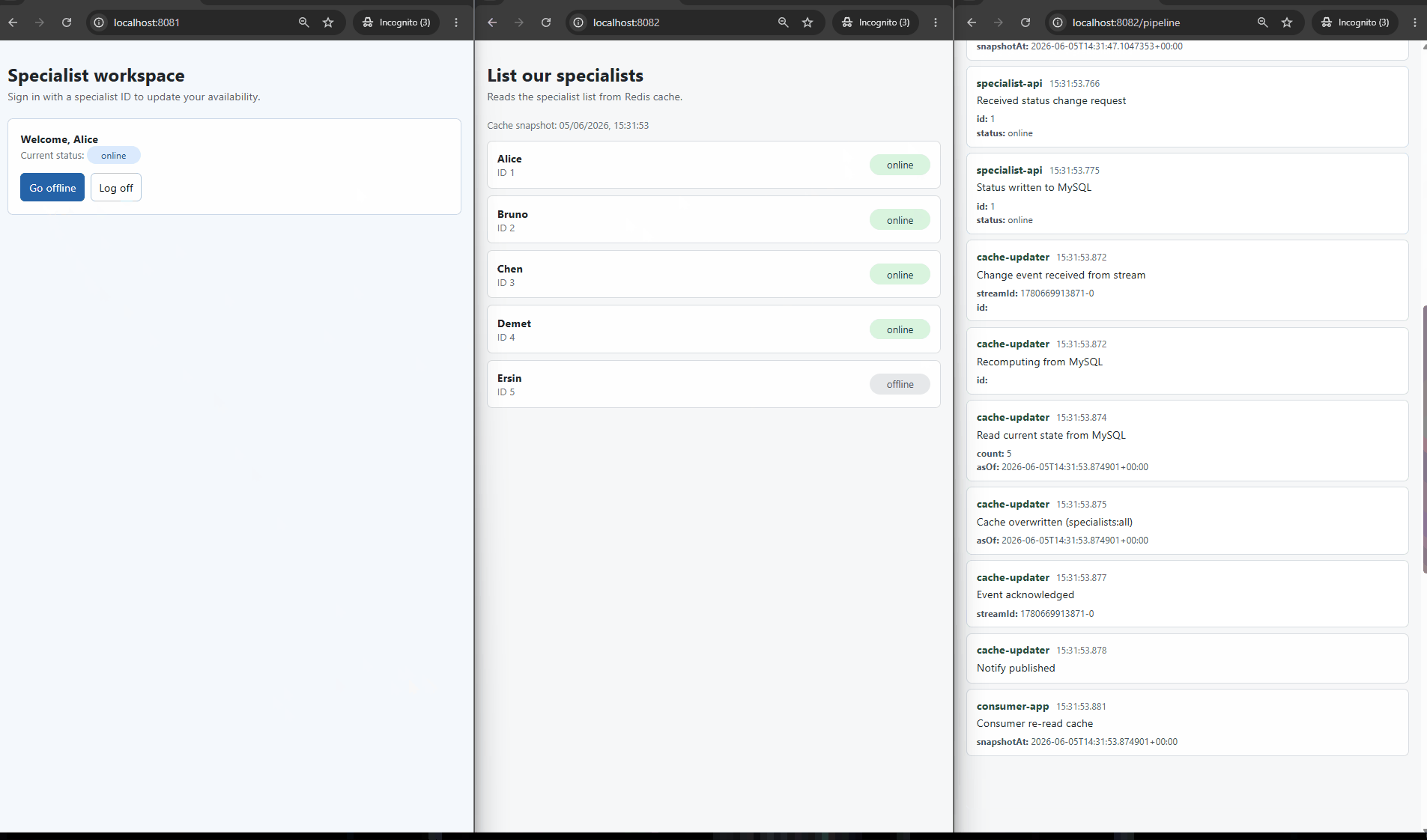
The flow goes like this:
- A specialist goes online, or a session ends.
- The change is written to MySQL, and only to MySQL — nothing touches the cache at this point.
- MySQL records the change in its binary log.
- Debezium reads the binary log and appends the change to a Redis Stream.
- A background worker reads from that stream.
- The worker queries MySQL for the current state and overwrites the cache.
- The worker acknowledges the event.
- The consumer side is told to re-read, and gets the fresh value from the cache.
To keep the example easy to follow, I use a single MySQL database here. The real situation has more than one source, but the idea does not change.
Redis does two jobs at once in this setup: it holds the cache, and it holds the stream of change events. One instance, two roles.
The key detail: recompute, do not patch
Once you are reacting to change events, there is one decision that matters more than the rest, and it is easy to get wrong.
When a change event arrives, it is tempting to take the value straight from the event and write it into the cache. I do not do that. The event is only a signal that something changed. When the worker receives it, it goes back to the database, reads the current state, and writes that into the cache.
The reason is that the data population logic has to live in one place, as a single source of truth. If I rebuilt the cached value from the contents of each event, I would be keeping a second copy of that logic, and I would have to keep it in sync forever. By recomputing from the database instead, there is only one place that knows how the value is built. It also means I can refresh or invalidate the cache regardless of what the event actually contains — the event just tells me “something about this specialist changed,” and the worker takes it from there. As a bonus, running the same recompute twice gives the same result, so a duplicate event does no harm.
Why is this acceptable?
It is fair to ask whether reading the database log like this is safe to run against a real system. A few things make me comfortable with it.
First, it required no change to the database. The binary log was already enabled, so turning this on did not change the database configuration — it only added another reader. There is some extra read load from that reader, but no schema changes, no triggers, and nothing written back.
Second, the database user that Debezium connects with has only replication and read permissions. It cannot insert, update, or delete anything. So the worst thing that can happen is a missed or delayed event, never corrupted data.
And because the cache is always rebuilt from the database, it corrects itself: if one update is somehow missed, the next event for that specialist rebuilds the value from the truth again.
There is one more choice worth explaining here. I used Redis Streams rather than plain publish/subscribe, for a specific reason. Publish/subscribe forgets a message if nobody is listening at that exact moment, so if the worker happens to be restarting when an event is published, the event is gone and the cache stays stale with nobody aware of it. A stream keeps the event until the worker acknowledges it, so a worker that was briefly down simply picks up where it left off.
Each cached value also carries a timestamp of when it was read from the database, so a reader can tell how fresh the data is, and a writer can check whether the cache already reflects their own change.
A note on caching terms
This post touches two different aspects of caching that are worth keeping apart. The first is the invalidation strategy — when and how a stale entry gets refreshed. The common options are a timer (TTL), invalidating on each write, event-driven invalidation, or versioned keys. What I describe here is event-driven invalidation, where the database change is the event.
The second is the read/write pattern — who talks to the cache and the database, and in what order. My setup is a mix here. Writes go straight to the database and skip the cache, which is close to a write-around pattern. But instead of waiting for the next read to refill the cache, the change event refills it ahead of time. So I get the clean separation of write-around, without the slow first read that usually comes after a change.
What I would do differently with proper services
I should be clear that this solution was shaped by its constraints. If changing the systems toward a microservices approach had been a viable option, I would not start here. With all writes going through services I control, I would publish a proper event from the service that owns the data, and update the cache from that, or use a write-through approach. That is cleaner, because the change and the event then come from the same place, on purpose, instead of being recovered from the database log after the fact.
That was not possible here. The writers are old, direct, and spread across several systems. CDC let me react to their changes without touching any of them. So I see this as a bridge rather than a destination: it solves the problem today, and it does not get in the way of moving to proper services later. When those services exist, the things that consume these events can stay the same — only the source of the events would change.
Try it
The full sample runs with a single docker compose command. Each item below links to the relevant part of the source code.
Root repo: alperenbelgic/cache-invalidation-debezium
- The specialist system status update SQL
-
The Debezium configuration that watches
demo.specialists - Where the cache updater handles each changed stream event
- Where the cache updater overwrites the Redis cache
Considerations
A few things worth keeping in mind before using something like this in production.
The binary log exposes everything. By default, the log records changes for the whole server, including sensitive tables. Debezium can be told to skip certain tables or columns, but that only controls what the pipeline processes — the data is still in the log and still readable over the connection. So depending on your binary log configuration, you may be exposing sensitive columns to whatever reads the log, and if your CDC tool runs off the database server, that data leaves the server. It is worth planning your log and column scope, and where the tool runs, with that in mind.
What to watch in production. The most useful signal is whether the worker keeps up with the stream: if the stream keeps growing, the worker is falling behind. I would also watch the number of events that were delivered but never acknowledged, which is a sign the worker is stuck; whether Debezium itself is keeping up with the log; Redis memory; and the log retention window compared to the longest time the worker might realistically be down. Using the cache timestamp, you can also alert when the data simply gets too old.
Other databases behave differently. This setup uses MySQL, where the binary log is purged on a schedule no matter what the consumer does, so a consumer that stays down too long loses events but does not threaten the database itself. PostgreSQL behaves differently: it holds its write-ahead log until the consumer acknowledges, which means a stuck consumer can fill the disk, so that needs watching. SQL Server is different again, using its own built-in CDC feature with capture jobs that have to be enabled per table and that write into change tables. It is worth checking how your specific database handles this before relying on it.